
Se você já leu outros posts aqui no blog sobre Ollama, sabe que a ferramenta resolve um problema concreto: permitir que qualquer pessoa ou organização rode LLMs diretamente na própria infraestrutura, sem enviar dados para servidores externos. Mas como exatamente isso funciona por dentro? O que acontece desde o momento em que você digita um comando no terminal até o modelo responder?
É isso que a gente vai destrinchar nesse post. Entender a arquitetura do Ollama não é só curiosidade técnica — é o que separa quem usa a ferramenta de quem consegue configurá-la, mantê-la e escalar ela dentro de uma organização.
Visão geral: as três grandes partes
A arquitetura do Ollama pode ser dividida em três blocos principais que se comunicam entre si.
O Ollama Model Library é o repositório remoto onde ficam armazenados todos os modelos disponíveis para download — Llama, Qwen, DeepSeek, Gemma, Mistral e muitos outros. É o ponto de partida: você acessa via browser, escolhe o modelo e o número de parâmetros, copia o comando e executa na sua máquina.
O Ollama Host é onde o Ollama de fato roda. Pode ser a sua máquina local, um servidor interno da empresa, ou até uma instância na AWS ou Azure. Dentro dele vive o Ollama Engine, que é o cérebro da operação — responsável por gerenciar os modelos baixados e os modelos em execução.
O Ollama Client é a interface de comando que você usa para interagir com o Ollama Engine. É ele que recebe os seus comandos e os repassa ao engine.
O diagrama abaixo ilustra como esses três blocos se conectam:
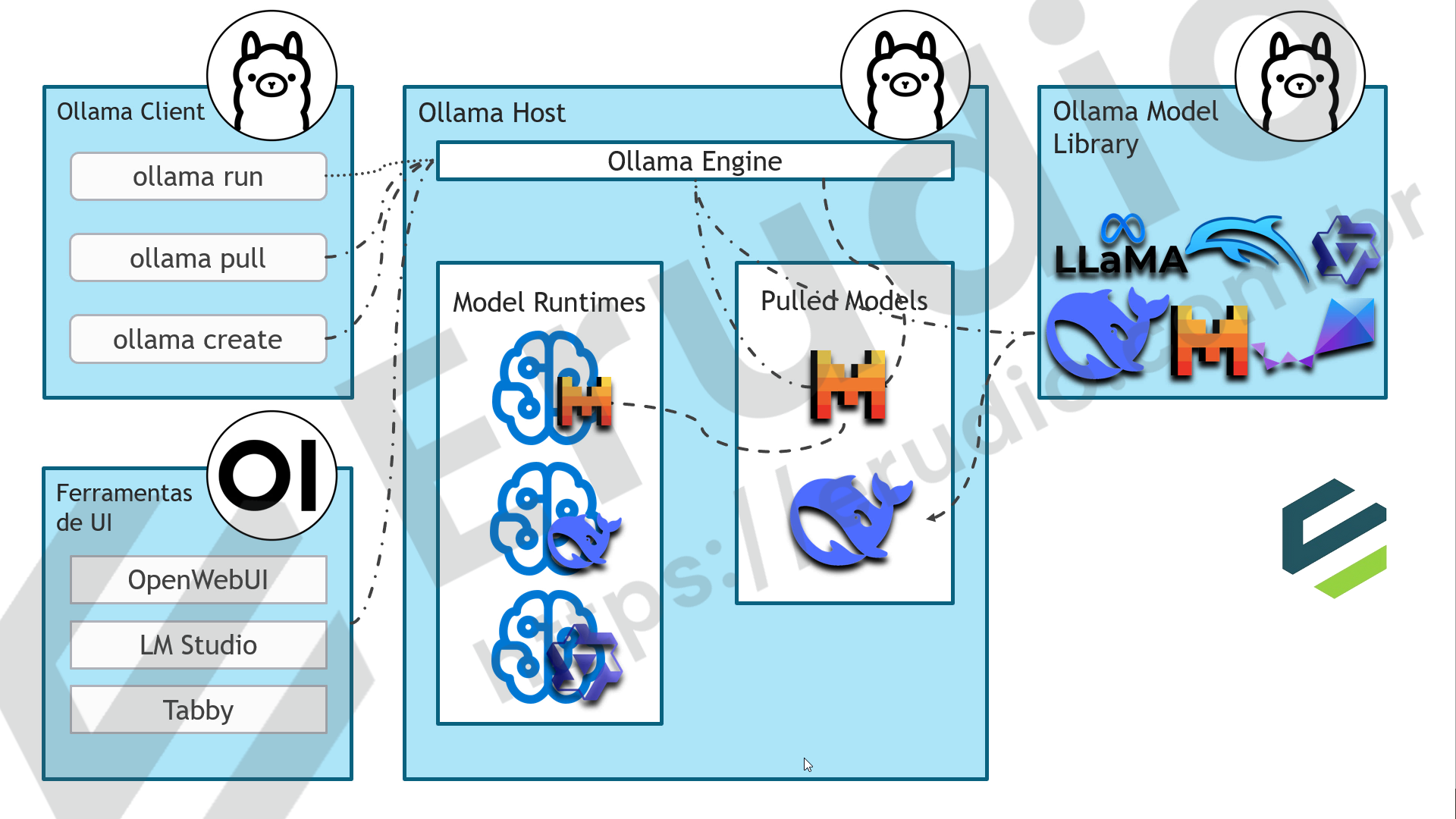
O Ollama Engine por dentro: Pulled Models e Model Runtimes
Dentro do Ollama Host, o Engine gerencia dois estados distintos em que um modelo pode se encontrar.
Pulled Models são os modelos que já foram baixados para a sua máquina mas que não estão em execução no momento. Quando você executa um ollama pull mistral, por exemplo, o Ollama vai até a Model Library, baixa o modelo e o armazena localmente. Ele fica disponível para uso sem precisar baixar novamente.
Model Runtimes são os modelos que estão de fato em execução — carregados na memória e prontos para responder. Quando você executa um ollama run mistral, o Engine verifica se o modelo já está nos Pulled Models. Se estiver, inicializa o runtime a partir dele. Se não estiver, vai até a Model Library, baixa, salva nos Pulled Models e só então inicializa o runtime. Você pode ter múltiplos runtimes ativos simultaneamente — um do Mistral, um do Dolphin, um do Llama — e o Engine gerencia todos eles.
Esse design é importante do ponto de vista corporativo: ele permite que a equipe de TI faça o pull de todos os modelos necessários de uma só vez, e a partir daí a infraestrutura opera sem precisar de conexão com a internet, já que tudo está armazenado localmente.
As duas formas de interagir com o Ollama
Existem duas maneiras de se comunicar com o Ollama Engine, e elas atendem perfis de usuário bem diferentes.
A primeira é o Ollama Client, que opera via terminal com comandos diretos como ollama run, ollama pull e ollama create. É a forma mais direta e a mais usada por desenvolvedores e times de infraestrutura. Também é o caminho para automações e integrações com outros sistemas.
A segunda são as ferramentas de UI, que se conectam ao Ollama Engine e oferecem uma interface gráfica para os usuários finais. A mais popular atualmente é o Open WebUI, que entrega uma experiência muito próxima ao ChatGPT — com histórico de conversas, troca de modelos, configurações de comportamento — sem que o usuário precise saber nada sobre linha de comando. Existem também o LM Studio e o Tabby, cada um com características próprias, mas o Open WebUI é o que tem o ecossistema mais maduro e a adoção mais ampla.
Para o contexto corporativo, essa separação é especialmente útil: o time técnico gerencia tudo pelo Client, enquanto os usuários de negócio interagem pelo Open WebUI sem nenhum atrito.
O Ollama Host não precisa estar na sua máquina
Um detalhe da arquitetura que passa despercebido mas que tem grande relevância para implantações corporativas: o Ollama Host e o Ollama Client são componentes separados e podem rodar em máquinas diferentes.
Isso significa que você pode ter um servidor dedicado rodando o Ollama Engine — com hardware robusto, GPU de alto desempenho, armazenamento adequado para múltiplos modelos — e qualquer máquina da rede pode usar o Client ou uma ferramenta de UI para se conectar a ele. É exatamente o modelo que faz sentido para uma empresa: uma infraestrutura centralizada, gerenciada pelo time de TI, acessível por todos os usuários da rede interna, sem que nenhum dado saia do perímetro da organização.
Conclusão
A arquitetura do Ollama é mais simples do que parece à primeira vista, mas foi projetada com flexibilidade suficiente para atender desde o desenvolvedor que quer experimentar um LLM no notebook até a empresa que precisa de uma solução robusta de Inteligência Artificial rodando na própria infraestrutura. Entender como o Engine, os Pulled Models, os Model Runtimes e as interfaces se relacionam é o primeiro passo para tirar o máximo da ferramenta — seja para uso pessoal ou para uma implantação corporativa de verdade.
Se quiser se aprofundar mais no tema, temos outros posts sobre Ollama aqui no blog.
Assista também: Arquitetura do Ollama Revelada: Entenda Como Funciona por Trás dos Bastidores
Treinamentos relacionados com essa postagem










 e GitHub Actions")






